【Omeka S モジュール開発】IIIFマニフェストにIIIF Content Search APIのURIを追加するモジュールを開発しました。
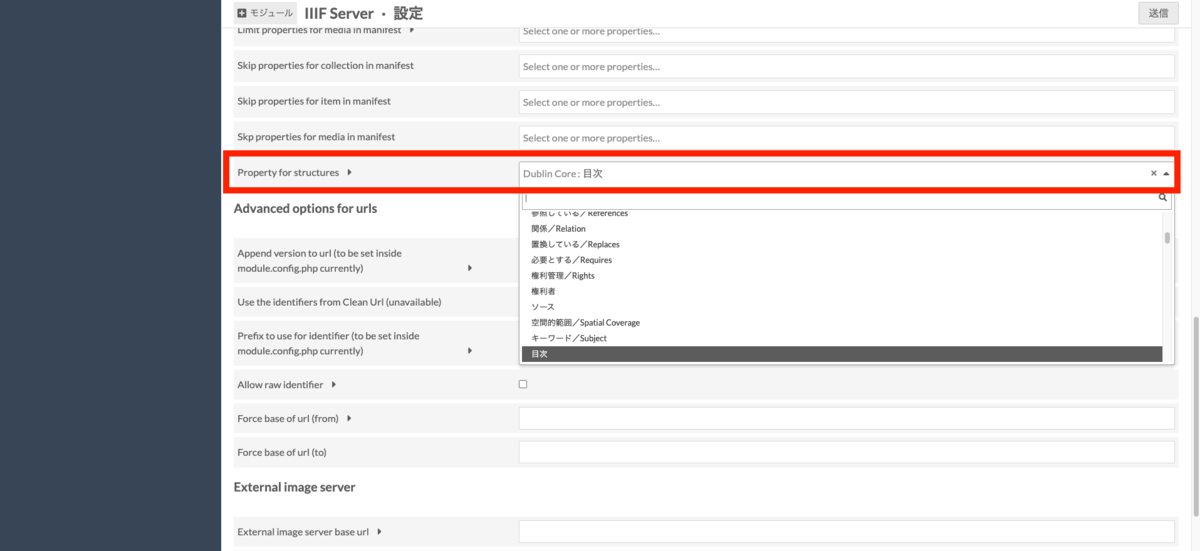
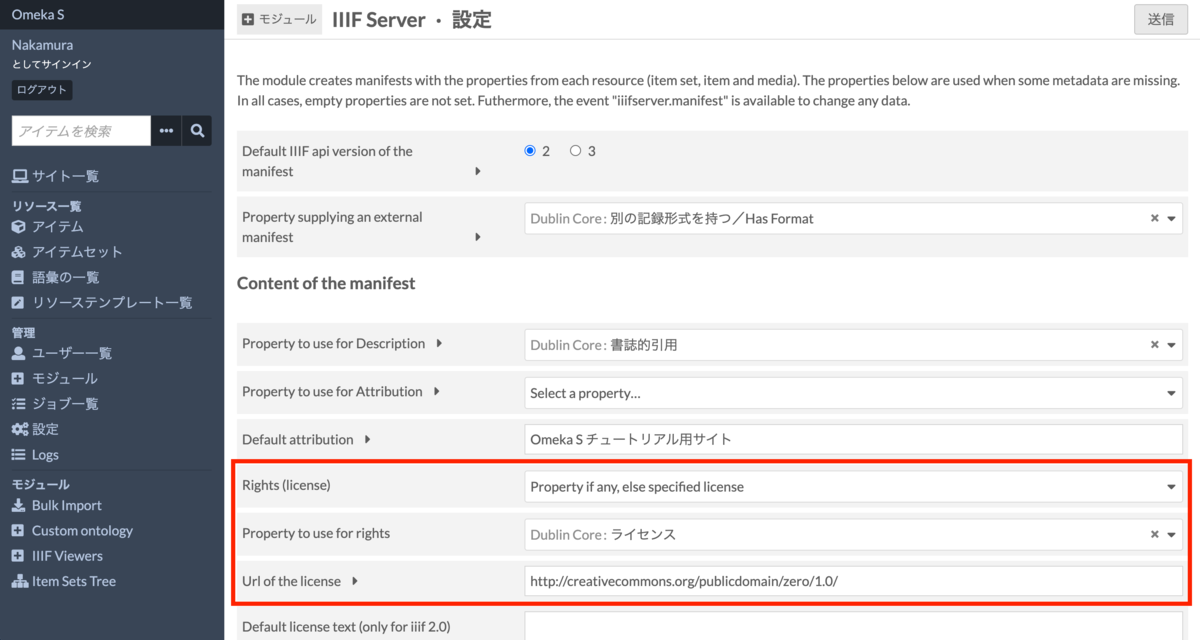
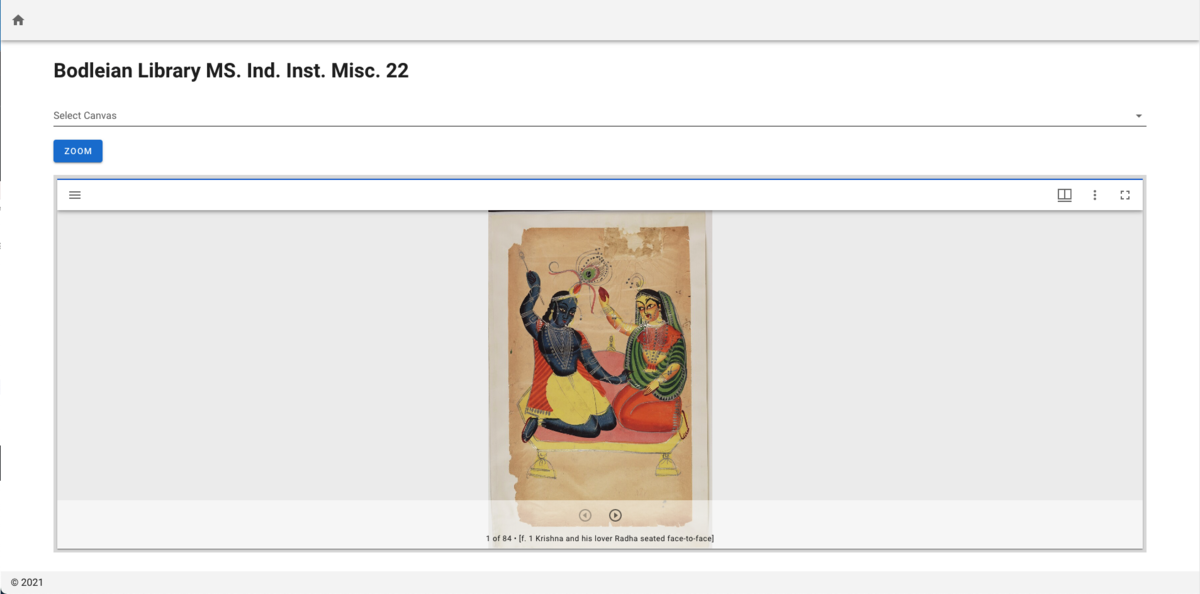
概要 IIIFマニフェストにIIIF Content Search APIのURIを追加するOmeka Sのモジュールを開発しました。 github.com IIIF Content Search APIを使用することにより、以下のように、Universal Viewer等でテキスト検索が可能になります。 本モジュールは、Omeka Sとは独立して提供されるIIIF Content Search APIを利用します。そのため、本モジュールを使用するには、このAPIの提供環境を別途用意する必要があります。この環境構築のコストに課題が残りますが、すでにIIIF Content Search APIの提供環境をお持ちで、かつOmeka Sでの利用を検討している方の参考になれば幸いです。 (IIIF Content Search APIの提供環境の構築については、改めて記事にできればと思います。) 背景 Omeka SのIIIF Serverモジュールは、Omeka Sに登録されたメタデータから、IIIFマニフェストファイルなどを生成するモジュールです。Omekaの様々なモジュールを開発されているDaniel-KM氏が主に開発されています。 omeka.org 本IIIF Serverモジュールの使い方については、以下で紹介しています。 youtu.be 本モジュールは、IIIF Presentation API 3.0への対応やIIIFコレクションの出力、目次の生成など、IIIF Presentation APIに関する様々な機能を提供していますが、本記事執筆時点(2022-02-11)において、IIIF Content Search APIに関する機能は提供していません。 なお、今回開発したモジュールとは別に、以下のIIIF Content Search API関連モジュールがあります。こちらはOmeka Sの内部でIIIF Content Search APIの提供環境を構築する大変便利なモジュールですが、PDFファイルに対するOCRテキストの利用が前提となっており、用途が限定的です。 github.com 機能紹介 本モジュールが提供する機能は単純で、以下に示すように、IIIF Content Search APIのURIを格納したプロパティを指定する設定機能を提供します。ここで設定したプロパティにURI形式の値を持つアイテムについて、IIIFマニフェストにIIIF Content Search APIのサービス情報を追記します。 生成されるIIIFマニフェストの例を以下に示します。(Omeka SのIIIF Serverモジュールによって生成された)IIIFマニフェスト内にIIIF Content Search APIのサービス情報が含まれていることを確認できます。 https://iiif.dl.itc.u-tokyo.ac.jp/repo/iiif/d507a810-cff7-4168-bc10-70a32a55920f/manifest ...