概要 The New York Public Libraryでは、Digital Collections APIを提供しています。
http://api.repo.nypl.org/
本記事では、このAPIの使い方の一例について説明します。
サインアップ まず以下のリンクをクリックして、サインアップを行います。
以下のようなフォームが表示されますので、必要な情報を入力します。
入力後、 Welcome to NYPL API という件名のメールが届きます。このメールの中に、 Authentication Token が記載されています。
メタデータの抽出 The New York Public Library Digital Collections APIではさまざまなendpointが提供されています。今回は以下のendpointを利用して、各アイテムのメタデータを抽出してみます。
http://api.repo.nypl.org/api/v1/items/item_details/[:id]
具体的には、以下のアイテムを例としてます。
https://digitalcollections.nypl.org/items/510d47e1-d3b0-a3d9-e040-e00a18064a99
そして、以下に示したメタデータの抽出を試みます。
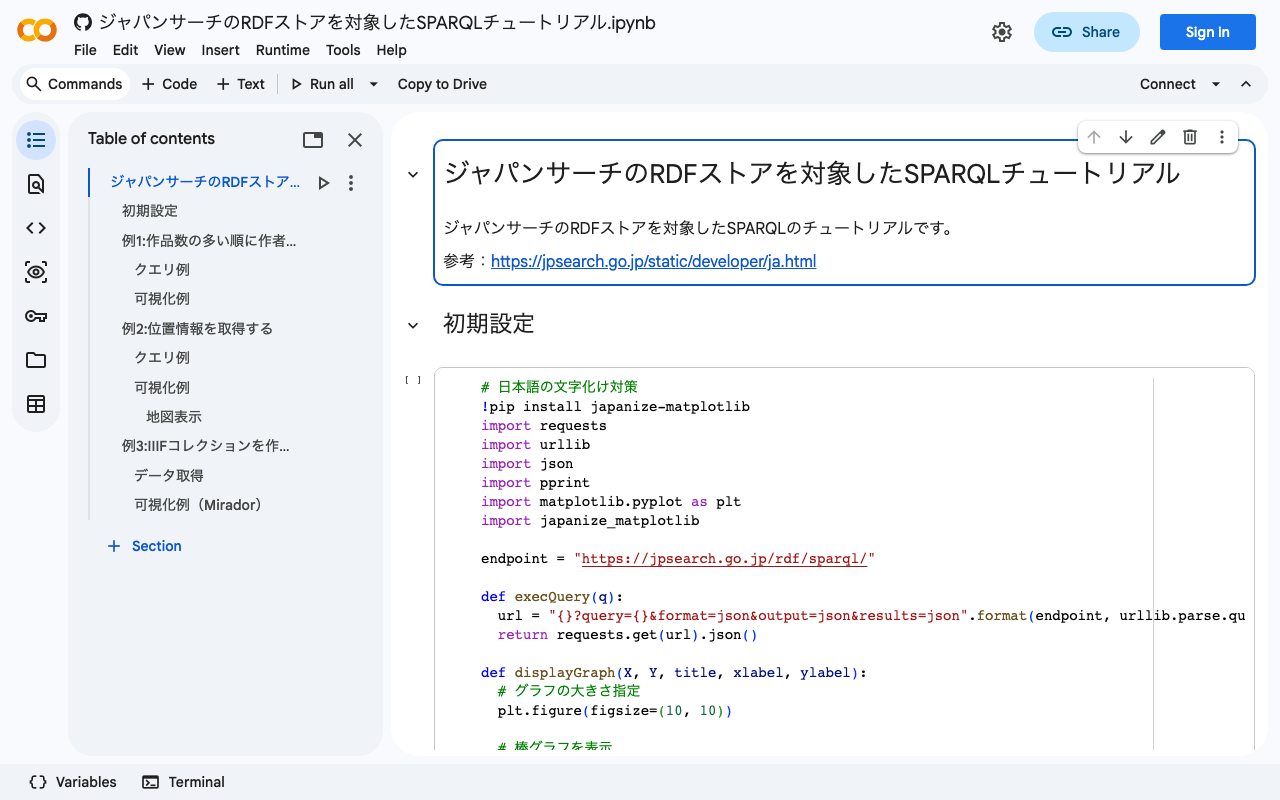
以下のGoogle Colabにメタデータの抽出サンプルプログラムを作成しました。参考になりましたら幸いです。
https://colab.research.google.com/drive/1sO9plTqraPwdBF61sArlD6k6pZRpfJL8?usp=sharing
上記プログラムを実行すると、例えば以下のようなメタデータが得られます。
{ "title": "Genji monogatari: Sakaki no maki|The Tale of Genji", "collection": " > Genji monogatari : Sakaki no maki", "dateIssued": "1650 (start)|1700 (end)", "place": "Kyoto", "identifier": "Hades Collection Guide ID (legacy): 443|Hades struc ID (legacy): 747877|Universal Unique Identifier (UUID): ce4bcd90-c60d-012f-9d19-58d385a7bc34" } まとめ APIを利用したデータ活用の参考になりましたら幸いです。
...