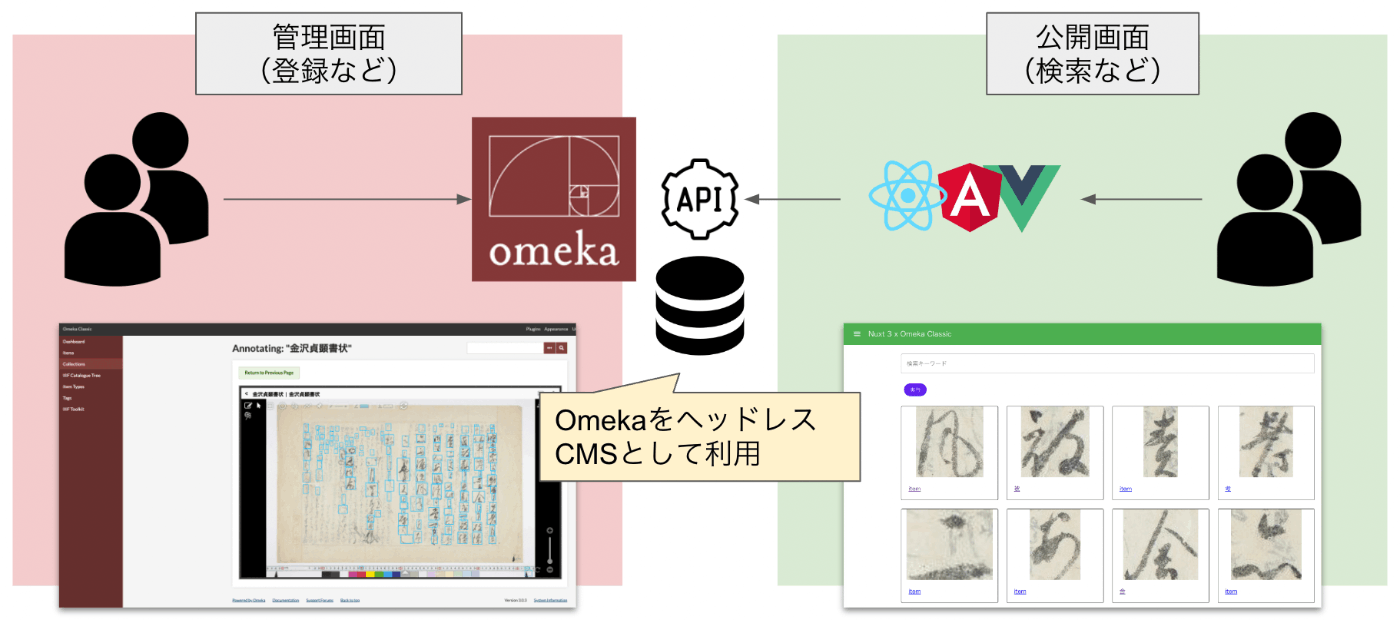
概要 現在Cultural Japanプロジェクトにおける検索アプリの更新を進めており、多言語データのアグリゲーションを行う必要がありました。本記事では、その方法に関する調査結果の備忘録です。
データ データとしては、以下のように、agential(人物を示す)フィールドに、id、ja、enの値を持つケースを想定します。
{ "agential": [ { "ja": "葛飾北斎", "en": "Katsushika, Hokusai", "id": "chname:葛飾北斎" } ] } 上記のデータに対して、idでフィルタリング処理などを行いつつ、言語設定に合わせてjaまたはenの値を表示することを想定します。
理想的には、aggregationの結果として、以下のようなデータを取得したいです。
(jaを指定した場合)
{ "buckets": [ { "key": "葛飾北斎", "id": "chname:葛飾北斎", "doc_count": 1 } ] } (enを指定した場合)
{ "buckets": [ { "key": "Katsushika, Hokusai", "id": "chname:葛飾北斎", "doc_count": 1 } ] } 方法1: nested aggregationの利用 以下の記事を参考に、nested aggregationを試します。
https://discuss.elastic.co/t/aggregeations-with-different-keys-and-values-label-and-id/274218
DELETE test PUT test { "mappings": { "properties": { "agential": { "type": "nested", "properties": { "id": { "type": "keyword" }, "ja": { "type": "keyword" }, "en": { "type": "keyword" } } } } } } PUT test/_doc/1 { "agential": [ { "ja": "葛飾北斎", "en": "Katsushika, Hokusai", "id": "chname:葛飾北斎" } ] } GET test/_search { "query": { "bool": { "filter": [ { "nested": { "path": "agential", "query": { "bool": { "filter": [ { "term": { "agential.id": "chname:葛飾北斎" } } ] } } } } ] } }, "_source": [ "agential" ], "aggs": { "agential": { "nested": { "path": "agential" }, "aggs": { "id": { "terms": { "field": "agential.id" } }, "label": { "terms": { "field": "agential.ja" } } } } } } この場合、以下のような結果が返却されます。
...