DrupalとAmazon OpenSearch Serviceを接続する
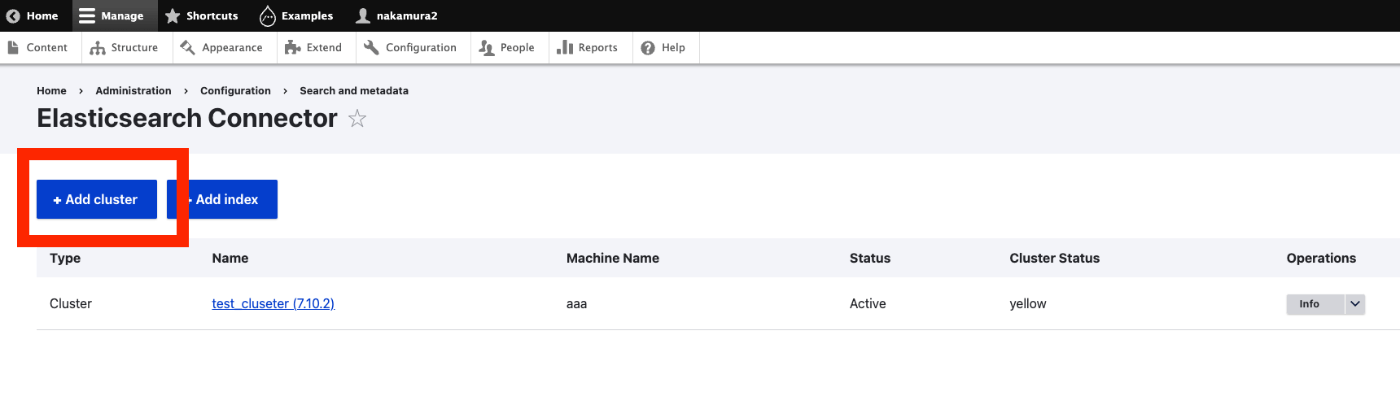
概要 DrupalとAmazon OpenSearch Serviceを接続する機会がありましたので、その備忘録です。以下の記事が参考になりました。 https://www.acquia.com/jp/blog/intergration-with-drupal-and-elasticsearch モジュールのインストール drupal/search_apiとdrupal/elasticsearch_connectorに加えて、nodespark/des-connectorをインストールする必要がありました。 (バージョンの指定方法など、改善の余地があるかもしれません。) composer require "nodespark/des-connector:^7.x-dev" composer require 'drupal/search_api:^1.29' composer require "drupal/elasticsearch_connector ^7.0@alpha" 続けて、以下で有効化します。 drush pm:enable search_api elasticsearch_connector DrupalをElasticsearchに接続する クラスタ 以下にアクセス /admin/config/search/elasticsearch-connector 「Add cluster」をクリックします。 そして、以下のように値を入力します。Amazon OpenSearch ServiceでBasic認証をかけている方法を前提としています。注意点として、「Server URL」に入力する値の末尾に、:443が必要でした。 Elasticsearchサーバーへの接続が成功すると、Cluster Statusに yellow や green と表示されます。 インデックス 次に、任意の作業ですが、インデックスを作成します。「Add index」ボタンを押して、nameだけ入力してみます。結果、以下のようにインデックスが作成されました。 Search APIの設定 今度は、Search API側の設定を行います。以下にアクセスします。 /admin/config/search/search-api サーバの追加 「Add Server」ボタンを押します。特に、BackendにElasticsearchを選択して、Clusterに先程作成したクラスタを選択します。 インデックスの追加 以下の画面には出ていませんが、「Datasources」のところで、「Content」を選択しています。また「Server」で、上記で作成したサーバを選択しています。 次に、末尾の「Save and add fields」ボタンをクリックします。 フィールドの追加 今回は最低限のフィールドとして、Titleを追加しておきます。 追加したフィールドに対するFulltext検索を可能とするために、「Type」を変更します。これらの設定は適宜変更してください。 再インデクシング 「Save changes」を押すと、以下のように、reindexingへのリンク(黄色)が表示されます。 ...










