概要 以下のAudio Presentation with Accompanying Imageを試した結果の備忘録です。
https://iiif.io/api/cookbook/recipe/0014-accompanyingcanvas/
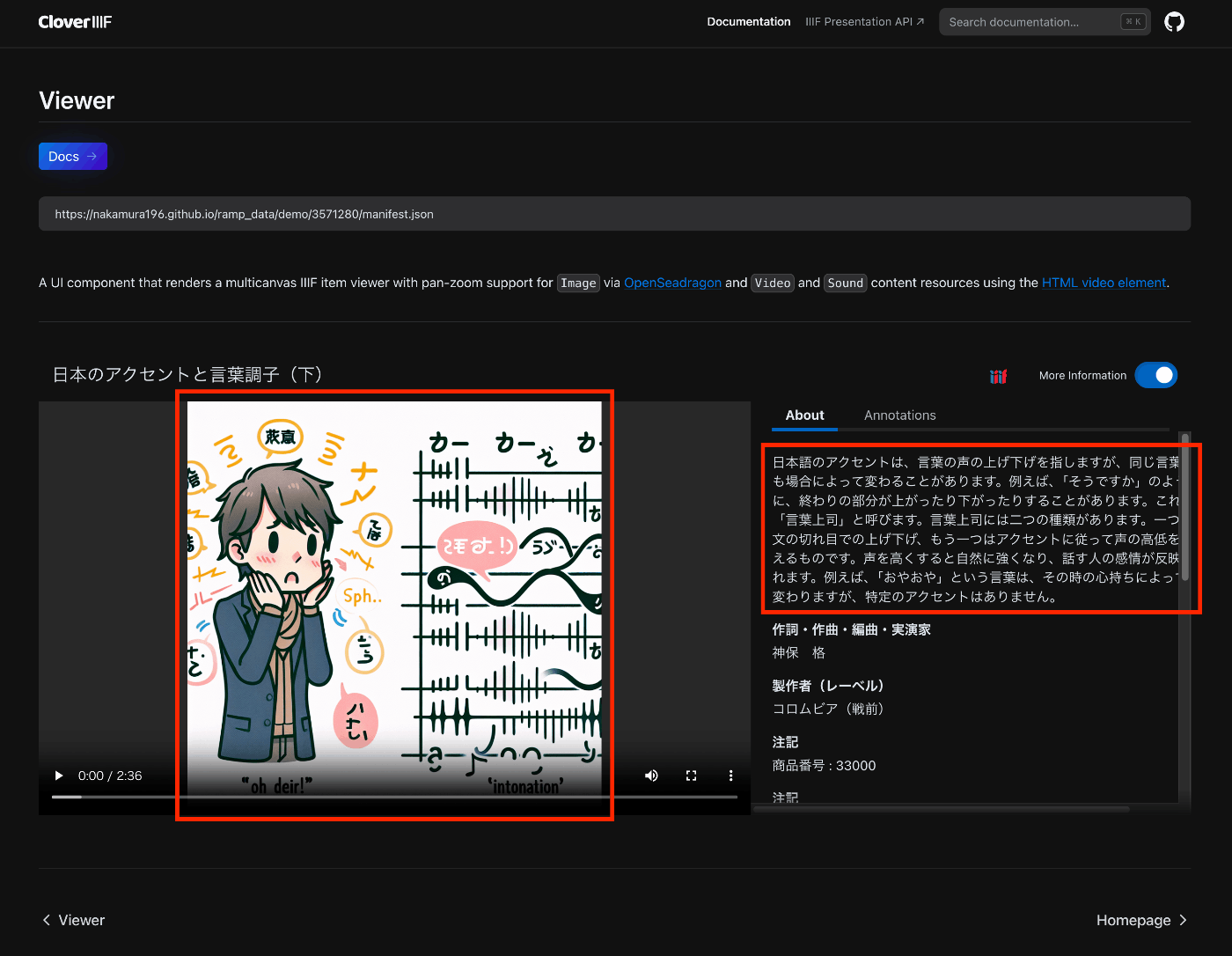
以下はCloverで表示した例ですが、設定した画像がプレイヤーに表示されます。
https://samvera-labs.github.io/clover-iiif/docs/viewer/demo?iiif-content=https://nakamura196.github.io/ramp_data/demo/3571280/manifest.json
マニフェストファイルの記述 以下に例を格納しています。
https://github.com/nakamura196/ramp_data/blob/main/docs/demo/3571280/manifest.json
具体的には、以下のように、CanvasにaccompanyingCanvasを追加する必要がありました。
{ "id": "https://nakamura196.github.io/ramp_data/demo/3571280/canvas", "type": "Canvas", "duration": 156.07999999999998, "accompanyingCanvas": { "id": "https://nakamura196.github.io/ramp_data/demo/3571280/canvas/accompanying", "type": "Canvas", "height": 1024, "width": 1024, "items": [ { "id": "https://nakamura196.github.io/ramp_data/demo/3571280/canvas/accompanying/annotation/page", "type": "AnnotationPage", "items": [ { "id": "https://nakamura196.github.io/ramp_data/demo/3571280/canvas/accompanying/annotation/image", "type": "Annotation", "motivation": "painting", "body": { "id": "https://nakamura196.github.io/ramp_data/demo/3571280/3571280_summary_image.jpg", "type": "Image", "height": 1024, "width": 1024, "format": "image/jpeg" }, "target": "https://nakamura196.github.io/ramp_data/demo/3571280/canvas/accompanying/annotation/page" } ] } ] }, わかりにくいですが、iiif_prezi3を使った記述例です。create_accompanying_canvas()によってaccompanyingCanvasを作成し、それをcanvasに関連づけています。
def add_accompanying_image(self): if self.verbose: print("Adding accompanying image") print(self.image_path) if os.path.exists(self.image_path): accompanyingCanvas = self.create_accompanying_canvas() self.canvas.accompanyingCanvas = accompanyingCanvas def create_accompanying_canvas(self): im = Image.open(self.image_path) w, h = im.size accompanyingCanvas = iiif_prezi3.Canvas(id=f"{self.prefix}/canvas/accompanying") anno_page, anno = self.create_image_annotation(w, h) accompanyingCanvas.set_hwd(height=h, width=w) accompanyingCanvas.add_item(anno_page) return accompanyingCanvas def create_image_annotation(self, width, height): anno_page = iiif_prezi3.AnnotationPage(id=f"{self.prefix}/canvas/accompanying/annotation/page") anno = iiif_prezi3.Annotation( id=f"{self.prefix}/canvas/accompanying/annotation/image", motivation="painting", body=iiif_prezi3.ResourceItem( id=f"{self.prefix}/{self.item_id}_summary_image.{self.image_format}", type="Image", format="image/jpeg", height=height, width=width ), target=anno_page.id ) anno_page.add_item(anno) return anno_page, anno (参考)画像ファイルの作成 国立国会図書館 歴史的音源(れきおん)では、画像データは提供されていないため、Dall-E 3を使用してサンプル画像を作成しました。
...