概要 IIIF Presentation API v3でsvgを使ったアノテーション記述を行う機会がありましたので、備忘録です。
方法 以下のように記述することで、svgを使ったアノテーションを表示することができました。
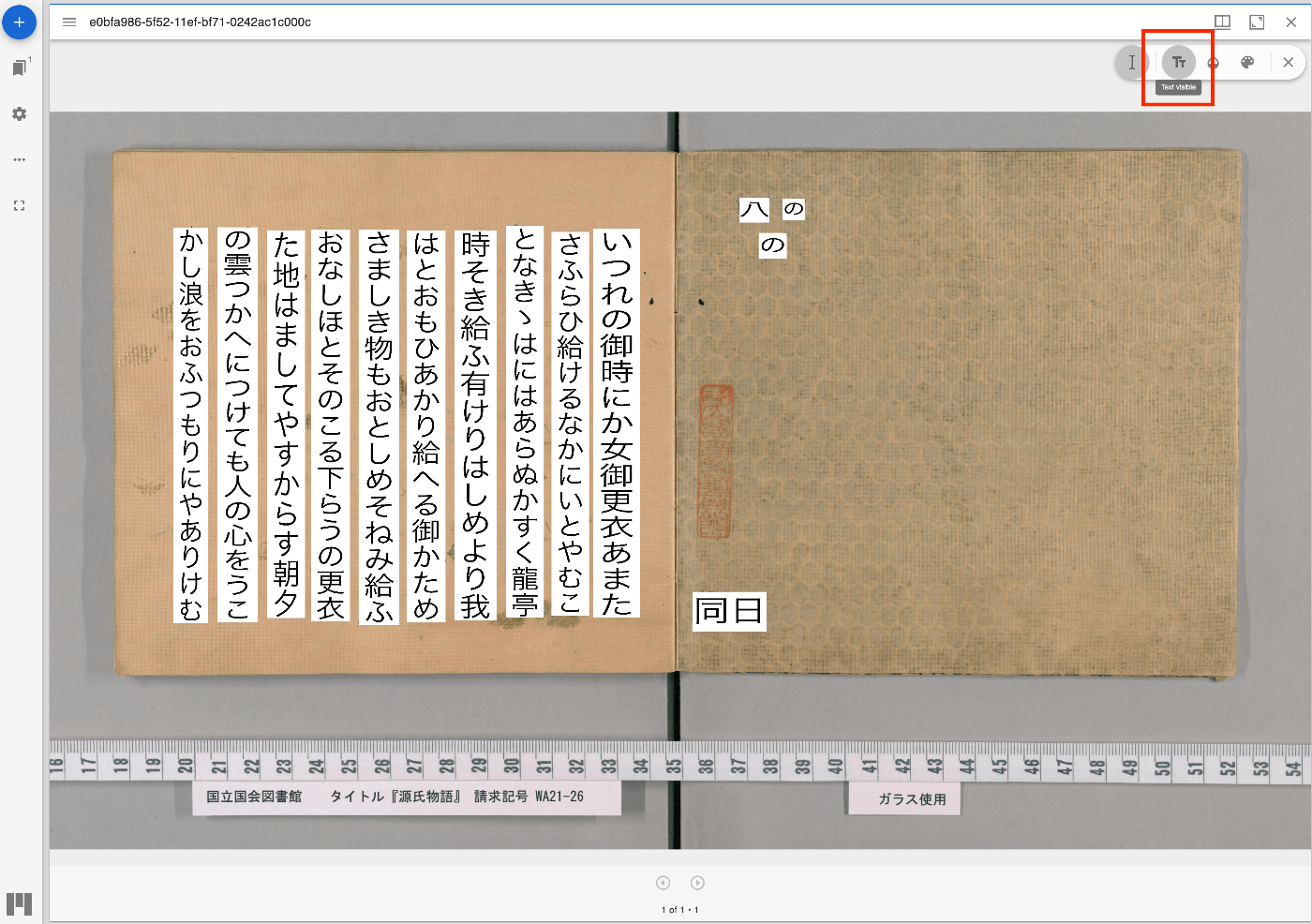
{ "@context": "http://iiif.io/api/presentation/3/context.json", "id": "http://127.0.0.1:62816/api/iiif/3/11/manifest", "type": "Manifest", "label": { "none": [ "きりつぼ" ] }, "rights": "http://creativecommons.org/licenses/by/4.0/", "requiredStatement": { "label": { "none": [ "Attribution" ] }, "value": { "none": [ "Provided by Example Organization" ] } }, "items": [ { "id": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1", "type": "Canvas", "width": 6642, "height": 4990, "label": { "none": [ "[1]" ] }, "thumbnail": [ { "format": "image/jpeg", "id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/genji/TIFF/A00_6587/01/01_0023.tif/full/200,/0/default.jpg", "type": "Image" } ], "annotations": [ { "id": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1/annos", "type": "AnnotationPage", "items": [ { "id": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1/annos/1", "type": "Annotation", "motivation": "commenting", "body": { "type": "TextualBody", "value": "<p>校異源氏物語 p.21 開始位置</p><p><a href=\"http://dl.ndl.go.jp/info:ndljp/pid/3437686/30\">国立国会図書館デジタルコレクション</a>でみる</p>" }, "target": { "source": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1", "type": "SpecificResource", "selector": { "type": "SvgSelector", "value": "<svg xmlns='http://www.w3.org/2000/svg'><path xmlns=\"http://www.w3.org/2000/svg\" d=\"M2798,1309c0,-34 17,-68 51,-102c0,-34 -17,-51 -51,-51c-34,0 -51,17 -51,51c34,34 51,68 51,102z\" id=\"pin_abc\" fill-opacity=\"0.5\" fill=\"#F3AA00\" stroke=\"#f38200\"/></svg>" } } } ] } ], "items": [ { "id": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1/page", "type": "AnnotationPage", "items": [ { "id": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1/page/imageanno", "type": "Annotation", "motivation": "painting", "body": { "id": "http://127.0.0.1:62816/api/iiif/3/11/image", "type": "Image", "format": "image/jpeg", "service": [ { "id": "https://iiif.dl.itc.u-tokyo.ac.jp/iiif/genji/TIFF/A00_6587/01/01_0023.tif", "type": "ImageService2", "profile": "level2" } ], "width": 6642, "height": 4990 }, "target": "http://127.0.0.1:62816/api/iiif/3/11/canvas/p1" } ] } ] } ] } 表示結果は以下です。
...