概要 Omeka SのOAI-PMH RepositoryモジュールでDeleteレコードを出力してみましたので、備忘録です。
背景 以下のモジュールを使用することにより、OAI-PMHのリポジトリ機能を構築することができます。
https://omeka.org/s/modules/OaiPmhRepository/
ただ、確認した限り、Deleteレコードを出力する機能はないようでした。
関連モジュール Omekaの標準機能では、削除されたリソースを保存する機能はないかと思います。
一方、以下のモジュールは削除されたリソースを保持する機能を追加します。
https://github.com/biblibre/omeka-s-module-Necropolis
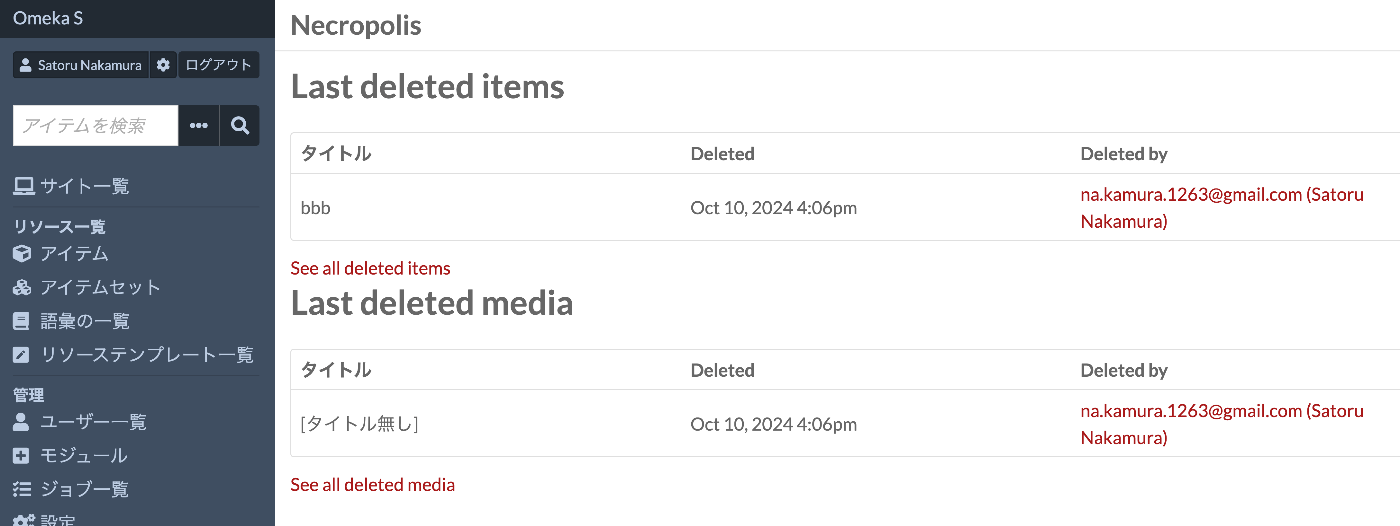
本モジュールを有効化することにより、以下のように、リソースがいつ誰によって削除されたかを記録できるようになりました。
OAI-PMH Repositoryモジュールへの応用 上記のモジュールで作成される削除されたリソースの情報が格納されるテーブルを使って、Deleteレコードの出力を試みます。
以下のファイルのlistResponse関数に追記します。
private function listResponse($verb, $metadataPrefix, $cursor, $set, $from, $until): void { /** * @var \Omeka\Api\Adapter\Manager $apiAdapterManager * @var \Doctrine\ORM\EntityManager $entityManager */ $apiAdapterManager = $this->serviceLocator->get('Omeka\ApiAdapterManager'); $entityManager = $this->serviceLocator->get('Omeka\EntityManager'); $itemRepository = $entityManager->getRepository(\Omeka\Entity\Item::class); $qb = $itemRepository->createQueryBuilder('omeka_root'); $qb->select('omeka_root'); $query = new ArrayObject; $expr = $qb->expr(); // 以下を追加 if ($set === 'o:deleted') { $settings = $this->serviceLocator->get('Omeka\Settings'); $namespaceId = $settings->get('oaipmhrepository_namespace_id', 'default_namespace'); // 削除済みレコードを necropolis_resource テーブルから取得する $deletedResourceRepository = $entityManager->getRepository(\Necropolis\Entity\NecropolisResource::class); // カスタムエンティティ // oaipmhrepository_expose_mediaに応じて、mediaとitemの取得を分ける $exposeMedia = $settings->get('oaipmhrepository_expose_media', false); // デフォルトはfalse(itemのみ) if ($exposeMedia) { $qb = $deletedResourceRepository->createQueryBuilder('necropolis_resource'); } else { // Itemのみを取得する $qb = $deletedResourceRepository->createQueryBuilder('necropolis_resource') ->andWhere('necropolis_resource.resourceType = :itemType') ->setParameter('itemType', 'Omeka\Entity\Item'); } // 日付フィルタリング if ($from) { $qb->andWhere($expr->gte('necropolis_resource.deleted', ':from')); $qb->setParameter('from', $from); } if ($until) { $qb->andWhere($expr->lte('necropolis_resource.deleted', ':until')); $qb->setParameter('until', $until); } // 結果の制限とオフセット $qb->setMaxResults($this->_listLimit); $qb->setFirstResult($cursor); $paginator = new Paginator($qb, false); $rows = count($paginator); if ($rows == 0) { $this->throwError(self::OAI_ERR_NO_RECORDS_MATCH, new Message('No records match the given criteria.')); // @translate } else { if ($verb == 'ListIdentifiers') { $method = 'appendHeader'; } elseif ($verb == 'ListRecords') { $method = 'appendRecord'; } $verbElement = $this->document->createElement($verb); $this->document->documentElement->appendChild($verbElement); foreach ($paginator as $deletedEntity) { // 削除されたリソースの情報をOAI-PMHレスポンスに追加 $header = $this->document->createElement('header'); $header->setAttribute('status', 'deleted'); // 削除済みレコードとして設定 $identifier = $this->document->createElement('identifier', 'oai:' . $namespaceId . ":" . $deletedEntity->getId()); $header->appendChild($identifier); $datestamp = $this->document->createElement('datestamp', $deletedEntity->getDeleted()->format('Y-m-d\TH:i:s\Z')); $header->appendChild($datestamp); $verbElement->appendChild($header); } // Resumption Token の処理 if ($rows > ($cursor + $this->_listLimit)) { $token = $this->createResumptionToken($verb, $metadataPrefix, $cursor + $this->_listLimit, $set, $from, $until); $tokenElement = $this->document->createElement('resumptionToken', (string) $token->id()); $tokenElement->setAttribute('expirationDate', $token->expiration()->format('Y-m-d\TH:i:s\Z')); $tokenElement->setAttribute('completeListSize', (string) $rows); $tokenElement->setAttribute('cursor', (string) $cursor); $verbElement->appendChild($tokenElement); } elseif ($cursor != 0) { $tokenElement = $this->document->createElement('resumptionToken'); $verbElement->appendChild($tokenElement); } } return; } ... OAI-PMH標準には合致していない実装方法ですが、setにo:deletedを指定すると、削除レコードを返却することができます。
...