概要 Mirador 3の mirador-annotations プラグインで、付与したアノテーションをダウンロードするための設定に関する備忘録です。
https://mirador-annotations.vercel.app/
背景 以下の記事で、アノテーションをGoogleのFirestoreに登録する方法を紹介しました。
ここで登録したアノテーションをダウンロードするにあたり、mirador-annotationsプラグインでダウンロードオプションが提供されていたので、その方法について紹介します。
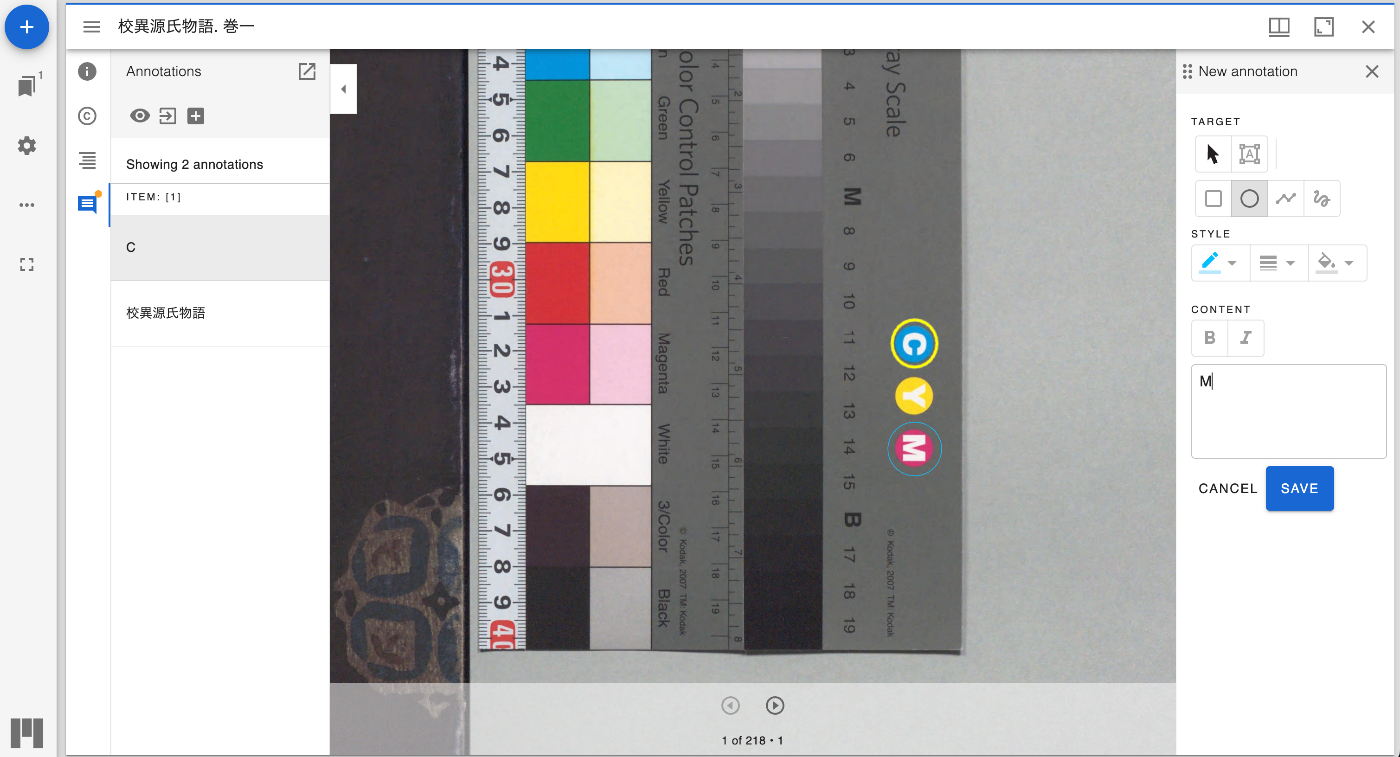
方法 以下がデモページのソースコードになりますが、exportLocalStorageAnnotationsというオプションをtrueにすることで、ダウンロードアイコンが表示されました。
import mirador from 'mirador/dist/es/src/index'; import annotationPlugins from '../../src'; import LocalStorageAdapter from '../../src/LocalStorageAdapter'; import AnnototAdapter from '../../src/AnnototAdapter'; const endpointUrl = 'http://127.0.0.1:3000/annotations'; const config = { annotation: { adapter: (canvasId) => new LocalStorageAdapter(`localStorage://?canvasId=${canvasId}`), // adapter: (canvasId) => new AnnototAdapter(canvasId, endpointUrl), exportLocalStorageAnnotations: false, // display annotation JSON export button }, id: 'demo', window: { defaultSideBarPanel: 'annotations', sideBarOpenByDefault: true, }, windows: [{ loadedManifest: 'https://iiif.harvardartmuseums.org/manifests/object/299843', }], }; mirador.viewer(config, [...annotationPlugins]); ダウンロードによって得られるJSONファイルの例は以下です。canvas毎にダウンロードできます。
{ "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1/annotations", "items": [ { "body": { "type": "TextualBody", "value": "<p>Cを変更</p>" }, "type": "Annotation", "motivation": "commenting", "target": { "selector": [ { "type": "FragmentSelector", "value": "xywh=5314,1983,195,206" }, { "type": "SvgSelector", "value": "<svg xmlns='http://www.w3.org/2000/svg'><path xmlns=\"http://www.w3.org/2000/svg\" d=\"M5314.21383,2086.96256c0,-56.89385 43.74418,-103.01543 97.70536,-103.01543c53.96118,0 97.70536,46.12158 97.70536,103.01543c0,56.89385 -43.74418,103.01543 -97.70536,103.01543c-53.96118,0 -97.70536,-46.12158 -97.70536,-103.01543z\" data-paper-data=\"{"state":null}\" fill=\"none\" fill-rule=\"nonzero\" stroke=\"#00bfff\" stroke-width=\"3\" stroke-linecap=\"butt\" stroke-linejoin=\"miter\" stroke-miterlimit=\"10\" stroke-dasharray=\"\" stroke-dashoffset=\"0\" font-family=\"none\" font-weight=\"none\" font-size=\"none\" text-anchor=\"none\" style=\"mix-blend-mode: normal\"/></svg>" } ], "source": { "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1", "type": "Canvas", "partOf": { "id": "https://dl.ndl.go.jp/api/iiif/3437686/manifest.json", "type": "Manifest" } } }, "canvasId": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1", "created": { "seconds": 1739524276, "nanoseconds": 522000000 }, "id": "exlXeaswdsiuhcFiLWSl", "userName": "中村覚", "manifestId": "https://dl.ndl.go.jp/api/iiif/3437686/manifest.json", "modified": { "seconds": 1739526046, "nanoseconds": 354000000 } }, { "motivation": "commenting", "id": "rx2JMkwtwuQDgbtAIOoO", "created": { "seconds": 1739524259, "nanoseconds": 611000000 }, "manifestId": "https://dl.ndl.go.jp/api/iiif/3437686/manifest.json", "body": { "type": "TextualBody", "value": "<p>校異源氏物語</p>" }, "userName": "中村覚", "canvasId": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1", "target": { "selector": [ { "type": "FragmentSelector", "value": "xywh=478,307,748,3424" }, { "value": "<svg xmlns='http://www.w3.org/2000/svg'><path xmlns=\"http://www.w3.org/2000/svg\" d=\"M478.38073,3732.45418v-3424.85175h748.39353v3424.85175z\" data-paper-data=\"{"state":null}\" fill=\"none\" fill-rule=\"nonzero\" stroke=\"#00bfff\" stroke-width=\"3\" stroke-linecap=\"butt\" stroke-linejoin=\"miter\" stroke-miterlimit=\"10\" stroke-dasharray=\"\" stroke-dashoffset=\"0\" font-family=\"none\" font-weight=\"none\" font-size=\"none\" text-anchor=\"none\" style=\"mix-blend-mode: normal\"/></svg>", "type": "SvgSelector" } ], "source": { "partOf": { "id": "https://dl.ndl.go.jp/api/iiif/3437686/manifest.json", "type": "Manifest" }, "type": "Canvas", "id": "https://dl.ndl.go.jp/api/iiif/3437686/canvas/1" } }, "modified": { "seconds": 1739524259, "nanoseconds": 611000000 }, "type": "Annotation" } ], "type": "AnnotationPage" } まとめ Mirador 3の mirador-annotations プラグインの利用にあたり、参考になりましたら幸いです。
...