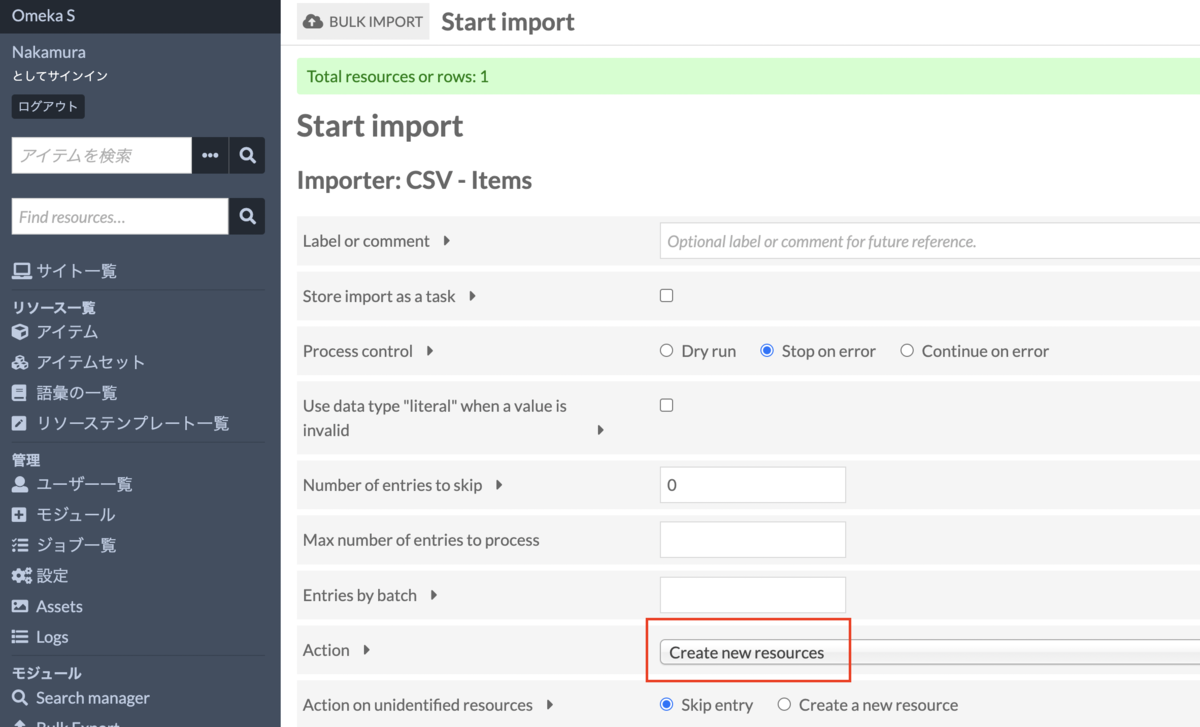
【備忘録】Maplatの使い方
古地図ビューアライブラリであるMaplatを使用してみましたので、使い方の備忘録です。 https://github.com/code4history/Maplat 上記のGitHubリポジトリのほか、以下のQiitaの記事なども参考になります。 https://qiita.com/tags/maplat?page=1 MaplatEditorのダウンロード 以下のページから、MaplatEditorの最新版をダウンロードします。 https://github.com/code4history/MaplatEditor/wiki データの作成 インストールしたMaplatEditorを立ち上げ、「新規作成」ボタンを押します。 必要なメタデータを入力します。以下の図に示す項目が必須項目です。 次に「対応点編集」タブに移動して、以下に示すように、対応点を追加します。 「データセット入出力」タブに移動して、「地図データエクスポート」ボタンを押します。 以下のように、<id名>.zipというファイルを適当な場所に保存します。 ダウンロードされたファイルを展開すると、以下に示すように、tmbs、tiles、mapsフォルダが格納されていることが確認できます。 アプリを作成する(ソースコードを利用する) 本記事では、ソースコードから利用する方法を説明します。npmコマンドが使用できる前提で話を進めます。 サンプルパッケージなどを利用して、より簡単にアプリを作成する方法が以下にまとめられています。こちらも参考にしてください。 https://github.com/code4history/Maplat/wiki/How-to-set-up-Maplat-Application 準備 適当なフォルダに移動して、以下に示すようなコマンドにより、ソースコードをダウンロードします。Maplatというフォルダが作成されます。 git clone https://github.com/code4history/Maplat.git 次に、以下のコマンドにより、ライブラリのインストールを行います。 cd Maplat npm install 次に、以下のコマンドにより、アプリケーションを立ち上げます。 npm run server 以下のURLでアプリケーションにアクセスすることができます。 http://localhost:8888/index.html アプリケーションの編集 まず、tmbs、tiles、mapsフォルダに、先にエクスポートした中身をそれぞれコピーします。 以下、mapsフォルダに追加した例を示します。 そして、<Maplatのダウンロードパス>/apps/sample.jsonを編集します。具体的には、以下に示すように、sources項目に、作成した地図のid(ここでは0001)を追加します。 その結果、以下のように、追加した画像がアプリケーションに表示されます。上記の入力値において、labelの値を変更することにより、アプリ上での表示名を変更することができます。 また、<Maplatのダウンロードパス>/public/index.htmlを編集することにより、表示内容を変更することができます。 一例として、以下に示すように、enableBorder: trueをoptionに追加してみます。 その結果、以下の図に示すように、画面右下に「地図境界表示」アイコンが表示され、選択すると、地図の境界が表示されます。 他にもさまざまな設定が可能です。設定内容については、以下が参考になります。 https://github.com/code4history/Maplat/wiki/How-to-set-up-Maplat-Application#4-appssamplejson%E3%81%AE%E8%A8%AD%E5%AE%9A%E6%96%B9%E6%B3%95 以上でアプリケーションの編集は終了です。今回は、新しく地図画像を追加しただけでした。実際には、上記のリポジトリではじめから同梱されている地図画像情報の削除等を行い、公開に必要なものだけに整理する必要があります。 参考 以下は参考情報ですが、<Maplatのダウンロードパス>/src/index.jsの以下の行をコメントアウトなどすると、コンソール画面に表示される内容を軽減できます。 https://github.com/code4history/Maplat/blob/19618d23a3d80cbde7db753cd769a41575527dd4/src/index.js#L1590 ビルド アプリケーションの編集が完了したら、ビルドを行います。以下のコマンドを実行します。 npm run build その結果、distとdist_packedフォルダが更新されます。 デプロイ ビルドした結果などをデプロイします。ここでは、AWSのS3にアップロードする方法を示します。 ...