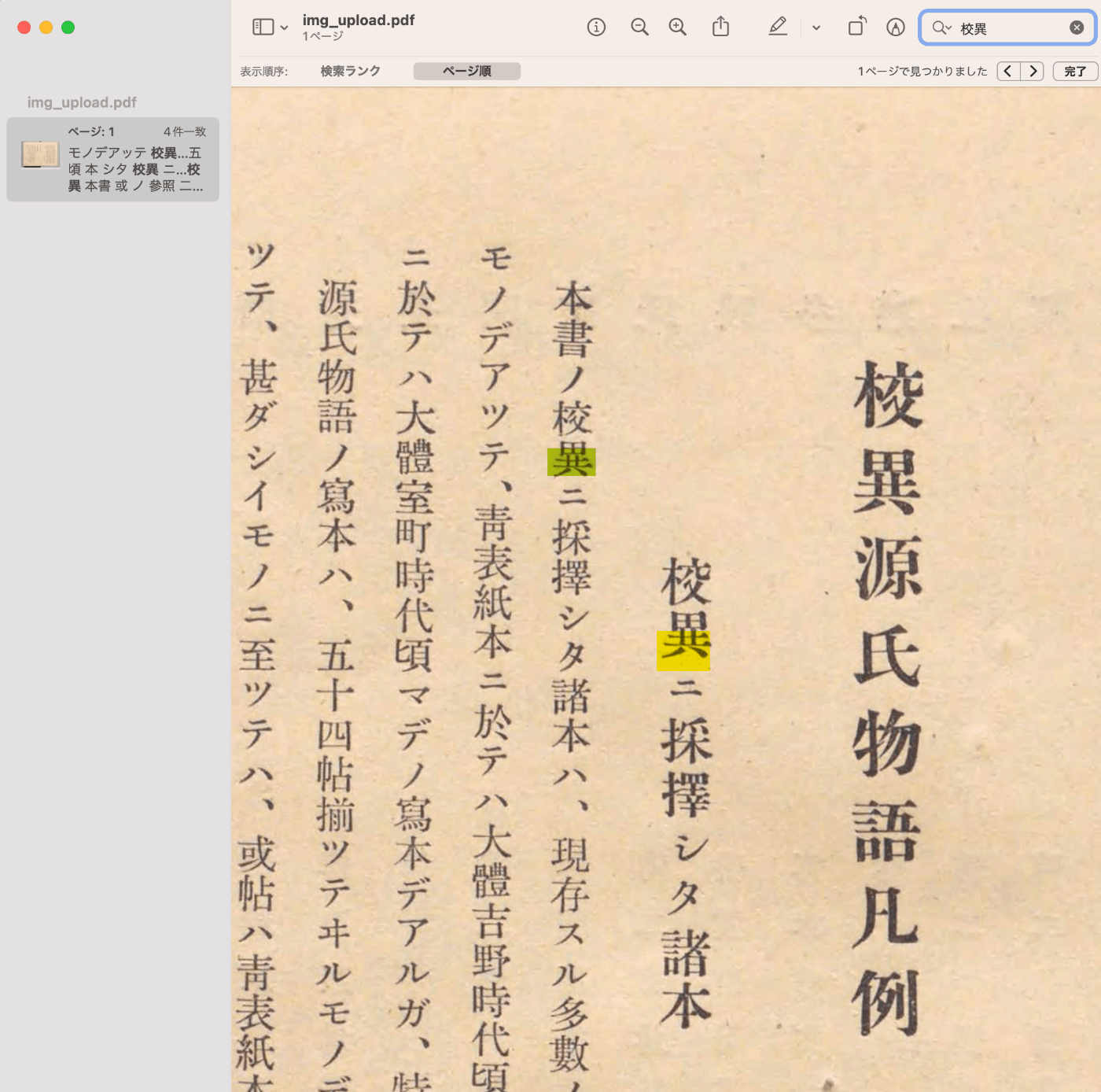
概要 共有ドライブに対して大量のファイルを作成した際、以下のように「Google ドライブでエラーが発生しました。」が表示され、ファイルを保存できなくなる事象に出会いました。
上記の原因として、以下に示す共有ドライブの制限に引っかかったことが考えられます。
https://support.google.com/a/answer/7338880?hl=ja
共有ドライブに保存できるアイテム数の上限
共有ドライブに保存できるアイテム数は最大 40 万個です。これにはファイル、フォルダ、ショートカットが含まれます。
1 日のアップロードの上限
個々のユーザーがマイドライブおよびすべての共有ドライブにアップロードできるのは、1 日あたり 750 GB までです。
2つ目の「1日のアップロードの上限」に引っかかってしまった場合には、1日待つほかないと思います。
一方、1つ目の「共有ドライブに保存できるアイテム数の上限」について、不要なファイルを削除することで対応することができます。
ただし、単にファイルを削除しただけでは、それらがゴミ箱に残ってしまい、(おそらく)先の制限を解除することができません。そこで、共有ドライブのゴミ箱を空にするスクリプトを探したところ、以下の記事に辿り着きました。
https://stackoverflow.com/questions/57764248/is-there-a-script-to-empty-google-team-drive-trash-related-folders
以下、上記で紹介されているスクリプトの使用方法について説明します。これにより、先述した「共有ドライブに保存できるアイテム数の上限」に引っかかってしまった際、その制限を解除することができます。
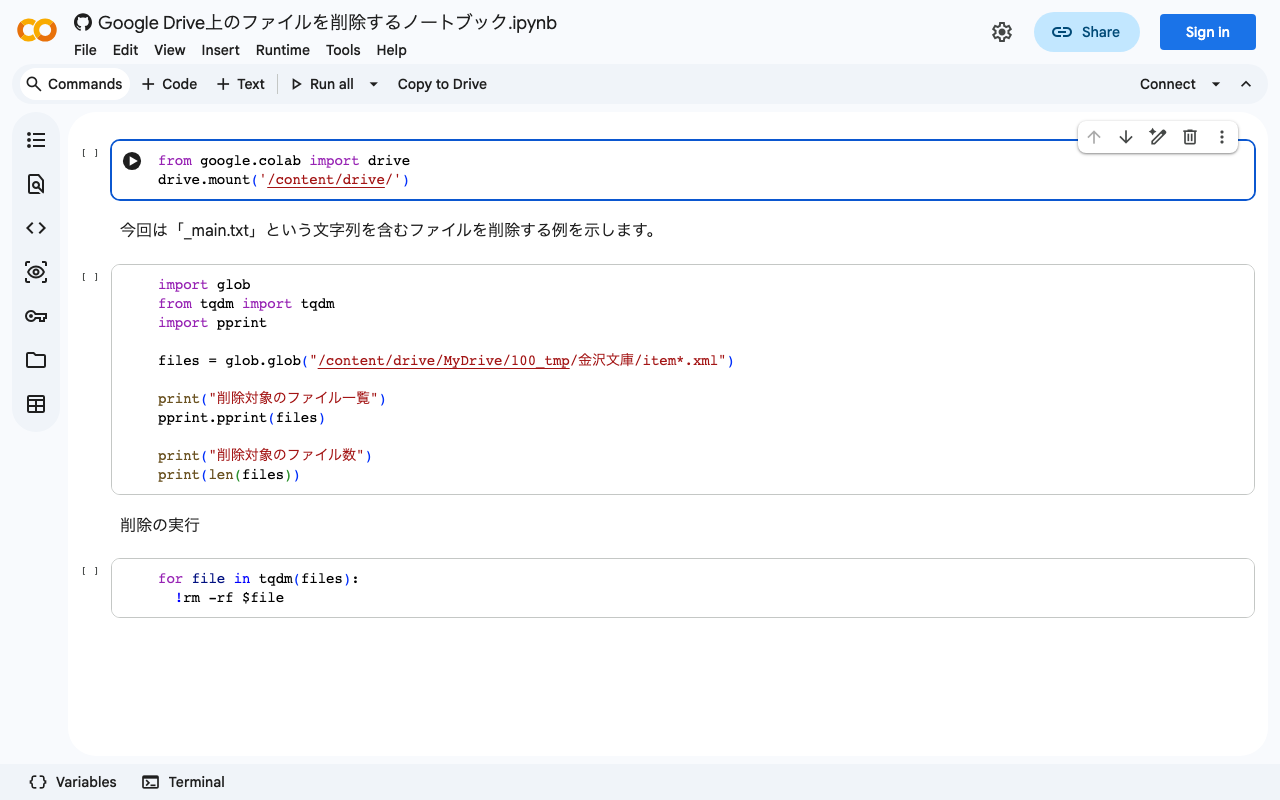
共有ドライブのゴミ箱を空にするスクリプトの実行方法 以下のスクリプトをコピペして利用します。
const driveId = "<共有ドライブのID>"; function myFunction() { var optionalArgs={driveId, 'includeItemsFromAllDrives':true, 'corpora': 'drive', 'supportsAllDrives': true, 'q':'trashed = true' } while(true){ var trashed=Drive.Files.list(optionalArgs).items; console.log("削除対象のファイルサイズ", trashed.length) for(var i=0;i<trashed.length;i++){ //console.log(i, trashed[i].id) try { Drive.Files.remove(trashed[i].id, {'supportsAllDrives':true}) } catch (e){ //console.log({e}) } } if(trashed.length == 0){ break } } } まず、以下のURLにアクセスしてください。
https://script.google.com/home
そして、下図に示す、「新しいプロジェクト」をクリックします。
先のスクリプトをコピペしてください。コピペ後、一行目の「driveId」を変更し、画面上部の「保存」ボタンを押してください。
次に、サービスを追加します。「サービス」から「Drive API」を追加してください。
その後「実行」ボタンを押します。
初回は承認が求められます。
以下に示すように、100件ずつ削除されていきます。
一定時間が経過すると、以下のようにエラーが発生します。その場合には、再度「実行」ボタンを押してください。
まとめ よりよい解決策があるかもしれませんが、「Google ドライブでエラーが発生しました。」等でお困りの方の参考になりましたら幸いです。
追記 2022.05.06 GASでは、スクリプトの実行時間が6分間という縛りがあるそうです。
...