AWS EC2を用いたVirtuoso RDFストアの構築
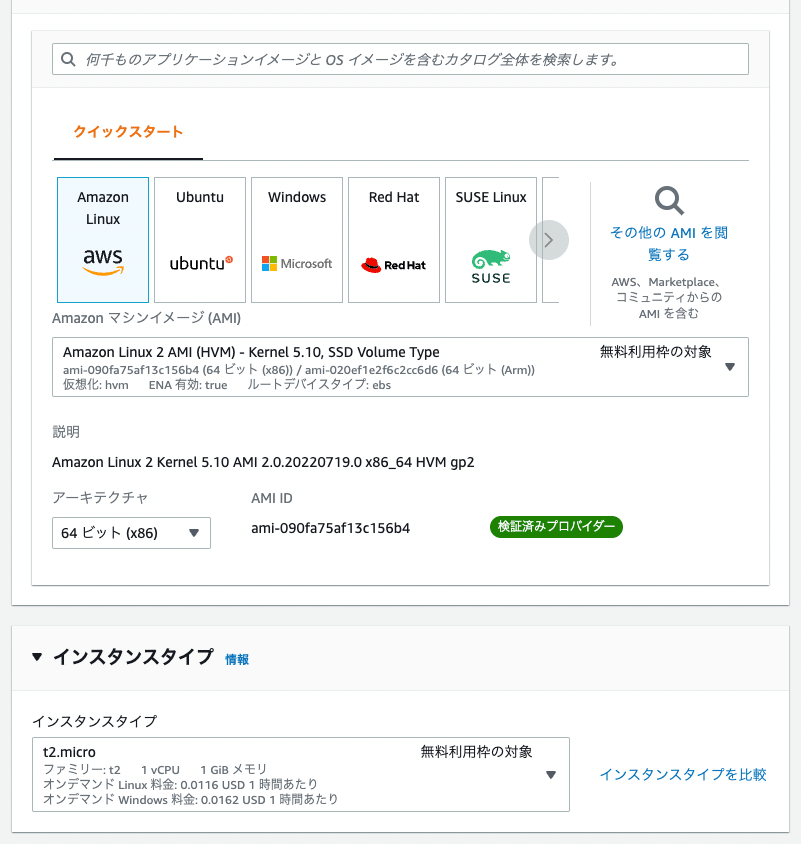
はじめに AWS EC2を用いたVirtuoso RDFストアの構築に関する備忘録です。独自ドメイン設定、HTTPS接続、Snorqlの設置、までを行います。 本記事以外にも、Virtuoso構築に関する有益な記事が多数存在しています。参考にしてください。 https://midoriit.com/2014/04/rdfストア環境構築virtuoso編1.html https://qiita.com/mirkohm/items/30991fec120541888acd https://zenn.dev/ningensei848/articles/virtuoso_on_gcp_faster_with_cos 前提 ACM Certificateは作成済みとします。以下の記事などを参考にしてください。 https://dev.classmethod.jp/articles/specification-elb-setting/#toc-3 EC2 まずEC2のインスタンスを作成します。 Amazon Linuxを選択し、インスタンスタイプはt2.microとしました。 ネットワーク設定については、「セキュリティグループを作成する」を選択し、「HTTPSトラフィックを許可する」と「HTTPトラフィックを許可する」の両方にチェックを入れます(以下の図では、後者にのみチェックが入っている状態ですのでご注意ください)。 インスタンスの状態が「実行中」になったら、画面右上の「接続」ボタンを押して、サーバに接続します。 接続後、以下を実行して、apacheサーバを立ち上げておきます。 sudo yum install httpd -y cd /var/www/html sudo vi index.html <p>test</p> sudo systemctl start httpd sudo systemctl enable httpd ELB作成 「ロードバランシング」の「ターゲットグループ」を選択します。 「Create target group」から、[Basic configuration]で「Instances」を選択して、あとは下図のように設定します。「VPC」は先ほど立ち上げたEC2インスタンスと同じものを選択しています。 「Register targets」の画面において、画面上部でインスタンスを選択して、「Include as pending below」ボタンをクリックします。すると、下図のように、選択したインスタンスが画面下部に移動します。 その後、「Create」ボタンを押します。 次に、「ロードバランサー」から「ロードバランサーの作成」を行います。 「Create Application Load Balancer」を選択し、以下のように「Network mapping」で複数のサブネットを選択します。 次がポイントですが、「Security groups」において、選択済みの「default」を削除して、先にEC2インスタンスの作成時に作成したセキュリティグループ「lanch-wizard-XX」など選択します。 また、「Listeners and routing」は、「HTTPS」を選択して、「Forward to」に先ほど作成したターゲットグループを選択してください。 ...