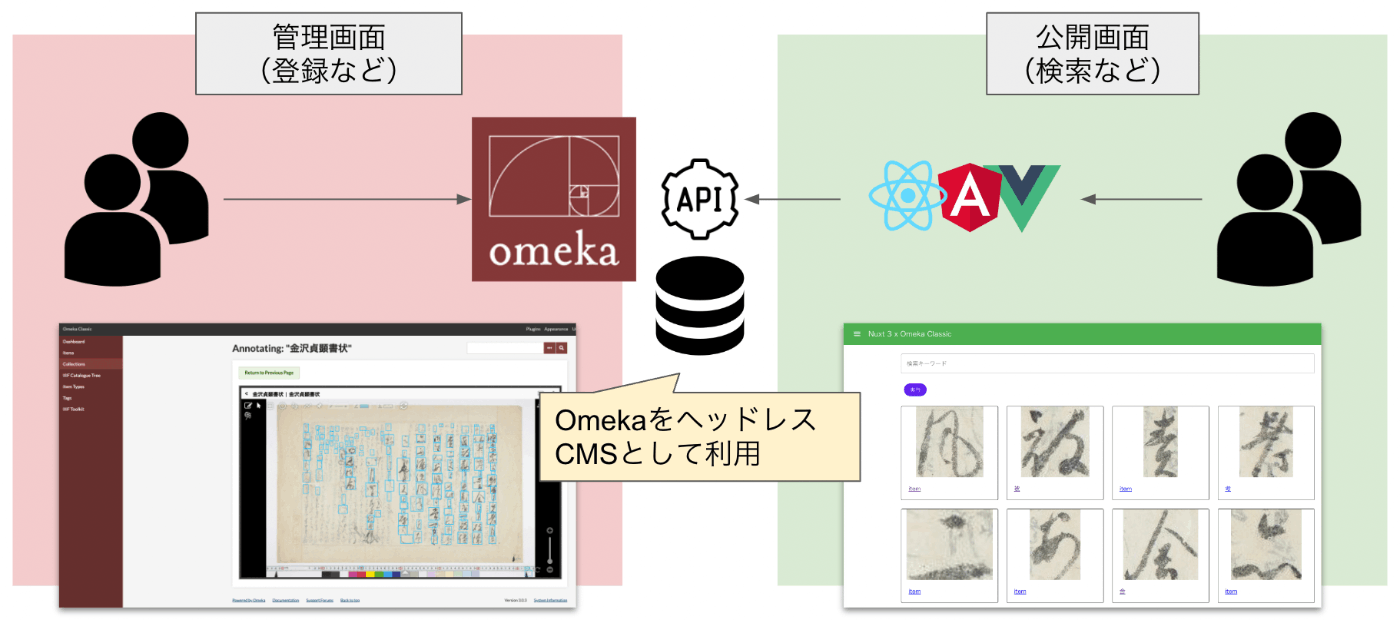
[RDF] Configuring URI Access to Redirect to the Snorql Interface
This is a continuation of the following article. This is a memo on configuring redirects so that accessing URLs like https://xxx.abc/data/123 redirects to https://xxx.abc/?describe=https://xxx.abc/data/123, using Japan Search’s RDF store as a reference. Japan Search example: https://jpsearch.go.jp/entity/chname/葛飾北斎 -> https://jpsearch.go.jp/rdf/sparql/easy/?describe=https://jpsearch.go.jp/entity/chname/葛飾北斎 Create a conf file like the following and place it in the appropriate location (e.g., /etc/httpd/conf.d/). RewriteEngine on RewriteCond %{HTTP_ACCEPT} .*text/html RewriteRule ^/((data|entity)/.*) https://xxx.abc/?describe=https://xxx.abc/$1 [L,R=303] Then restart Apache. systemctl restart httpd This enables redirecting to the Snorql interface. ...