Bulk Importによる一括登録および更新の方法について、以下の記事を作成しました。
上記において、リソースクラスの登録方法を示していなかったため、本記事で追記します。また、Bulk Importモジュールの設定内容の編集方法についても補足します。
リソースクラスの登録
リソースクラス登録用のCSVファイルのサンプルを以下に用意しました。
https://github.com/omeka-j/Omeka-S-module-BulkImport-Sample-Data/blob/main/resource_class/sample.csv
ポイントとして、列名を「o:resource_class」とします。また、セルの値は、Omeka S上でTermとして確認できる値を入力します。例えば、dctype:Collectionなどを入力します。
その他:ダミー列の用意
一部のプロジェクトにおいて、CSVファイルの1列目がうまく処理されないことがありました。そのため、1列目にダミー列を用意したほうが良い場合があります。上記のサンプルCSVでも、ダミー列を設けています。
Bulk Importモジュールの使い方の補足
以下のように、画面左のBulk ImportのCofigurationから、設定画面に遷移します。以下、ReaderとProcessorの設定方法について説明します。
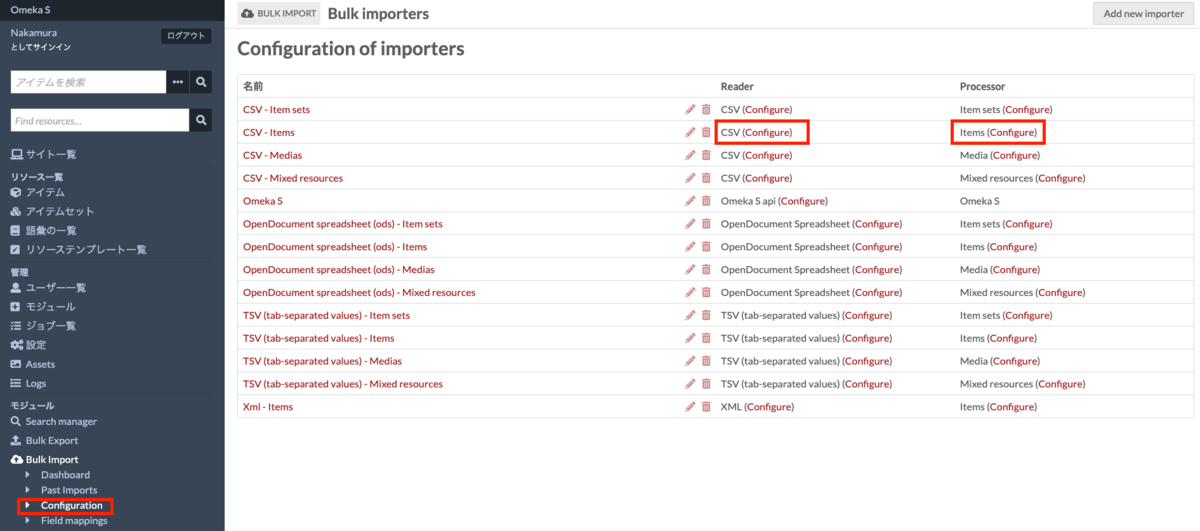
なお、一般的な利用においては、この設定はデフォルトのままで問題ありません。
Readerの設定
以下がReaderの設定画面です。この設定を変更することで、各組織や研究プロジェクト等におけるデータ作成ルールに合致するようにカスタマイズできます。
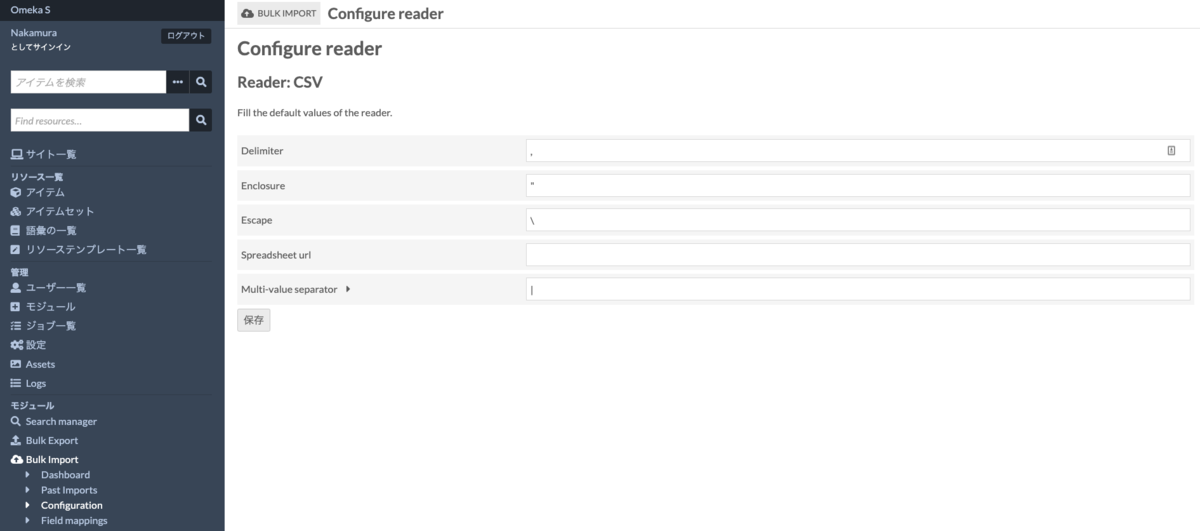
例えば「Multi-value separator」の値は、セル内に複数の値を入力する際の区切り文字です。デフォルト設定では、「|(パイプ)」が与えられていますが、他の区切り文字に設定することも可能です。
なお、上記の設定はデフォルトの設定を変更するもので、CSVファイルの登録する度に、この設定(区切り文字など)を変更することもできます。
Processorの設定
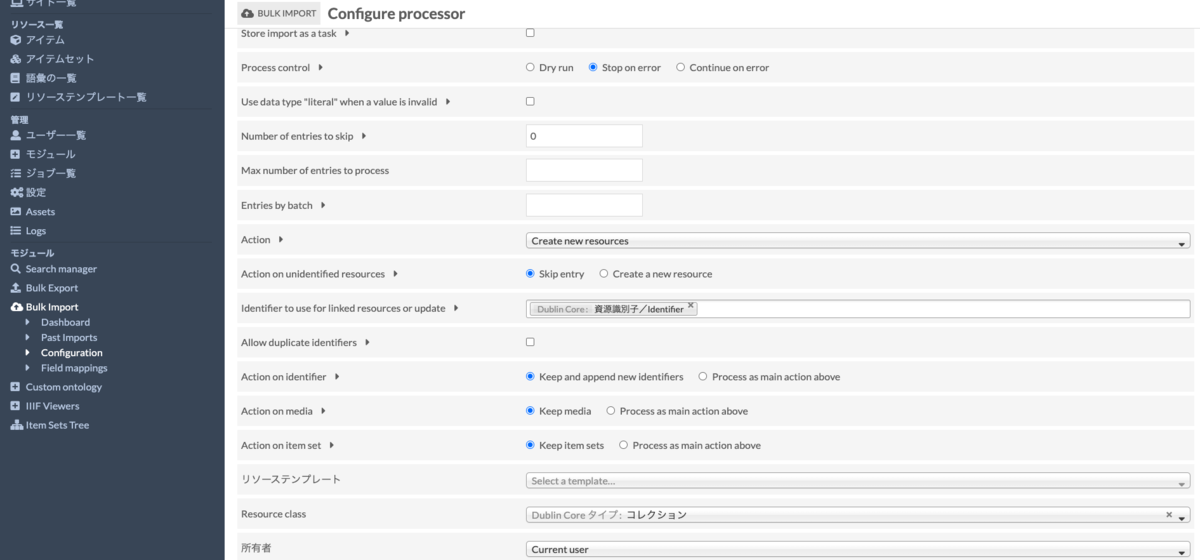
以下は、Processorの設定画面です。例えば、「リソーステンプレート」を編集することで、デフォルトのリソーステンプレートを指定することができます。その他、Resource classや所有者などのデフォルト値も設定することができます。
その他、さまざまな設定が可能ですので、色々と試行錯誤してみることをお勧めします。
まとめ
上記のようにデフォルトの設定を変更することで、CSVファイルを登録する際の設定漏れを防ぐことができます。各組織や研究プロジェクト等におけるルールに応じた設定を行い、作業効率の向上や操作ミスの軽減につながれば幸いです。